
The Randomized QuickSort sorting algorithm is a foundational randomized algorithm whose randomized analysis is always imperative to absorb and internalize. In this post, we explore the very simplified approach to its analysis with the use of probabilistic techniques rather than a brute-force expected run-time analysis.
The procedure and intuition behind this algorithm are comprehensively described in a previous post, and the key probabilistic background that will be employed here can also be found in a previous post. Here, we first begin with a discussion addressing the fact that we analyze expected run-time not average-case run-time, and then move on to some empirical results that motivate the discussion of expected run-time analysis (more intuitive motivation can be found in my previous post). Then we will quickly discuss the brute-force method to simply emphasize the goriness of the analysis; then we lastly move on to a simpler and cleaner analysis.
Some facets of this analysis are adapted from Introduction to Algorithms, 3rd Ed., Chapter 7 by Cormen et. al., and also from Prof. C. Seshadhri’s lecture notes from his CSE 290A course at UC Santa Cruz; these notes can be found here, and the lecture recording can be found here.
Expected Run-time vs. Average Run-time
When I first explored QuickSort’s analysis it was labeled by “average run-time”, but an average over what? Is it over all possible input arrays? This notion makes sense for a deterministic algorithm where we want to see the behavior of the algorithm over all input, and we call this the average run-time of the algorithm.
Applying this notion to our problem setting, the average run-time for deterministic QuickSort is then  since, on average, the last element of the array is a balanced pivot. However, this isn’t very helpful since we have a very real worst-case input of a sorted or reverse sorted array input.
since, on average, the last element of the array is a balanced pivot. However, this isn’t very helpful since we have a very real worst-case input of a sorted or reverse sorted array input.
On the other hand, for Randomized QuickSort, given some array  , the expected run-time of Randomized QuickSort is the expected run-time over all possible ways the randomized algorithm could sort the array. This makes sense since we choose our pivot randomly, so there can be different run-times, so we look for the expected run-time. As we will derive further in this blog, this expected run-time is also
, the expected run-time of Randomized QuickSort is the expected run-time over all possible ways the randomized algorithm could sort the array. This makes sense since we choose our pivot randomly, so there can be different run-times, so we look for the expected run-time. As we will derive further in this blog, this expected run-time is also  .
.
From above we see that both the expected run-time and average run-time are asymptotically the same (both are  ). This is special to QuickSort since the randomization of choosing the pivot is the only difference between Randomized QuickSort and deterministic QuickSort, and so with randomization of input arrays, the benefit of randomly choosing a pivot is essentially nullified. This, although not formal, can give some intuition as to why both the expected run-time and average run-time are similar. For the formal conclusion, it requires some intensive probability theory and conditional probability, so rather we will explore this in the section to empirically confirm our conclusions here.
). This is special to QuickSort since the randomization of choosing the pivot is the only difference between Randomized QuickSort and deterministic QuickSort, and so with randomization of input arrays, the benefit of randomly choosing a pivot is essentially nullified. This, although not formal, can give some intuition as to why both the expected run-time and average run-time are similar. For the formal conclusion, it requires some intensive probability theory and conditional probability, so rather we will explore this in the section to empirically confirm our conclusions here.
Empirical Motivation
Here we wish to explore some empirical results on the number of array comparisons made by both the deterministic and randomized versions of QuickSort. As a disclaimer, the results are quite underwhelming hinted by our discussion regarding the two different metrics for run-time.
We counted the number of array comparisons (which we will deem as the run-time in our case since it is arguably the most expensive operation in our QuickSort algorithms) made by the regular deterministic QuickSort with a random array input. We did this over 1,000 arrays of size 1,000 (note we ran QuickSort 50 times on the same array to make the magnitude the same as for the next plot to aid in comparing the two), and the distribution of run-time is shown below.
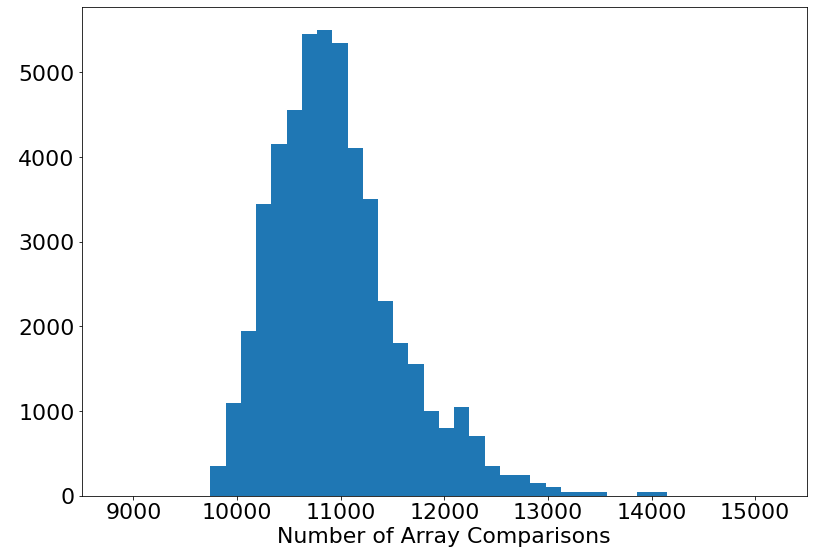
Then we do the same for Randomized QuickSort, but this time on the same array we ran the algorithm 50 times as to get a nice idea of the distribution of Randomized QuickSort on randomized input arrays which is shown below.
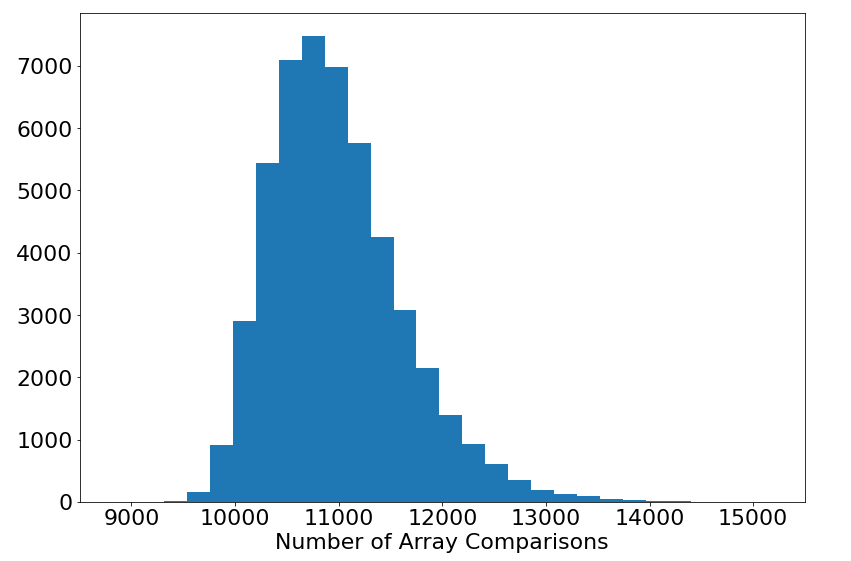
As foreshadowed, the plots are extremely similar in their shape and mean, and in fact, this was expected by our analysis in the last section that the expected running time and average running time would be asymptotically the same.
Then this begs to ask what even is the advantage of Randomized QuickSort? What it guarantees is an expected run-time of on any given input, and without the randomness, we have a deterministic run-time for a given input which isn’t desirable all the time. This can be seen in the following plot which depicts the run-time distribution for some given instance (over 1,000 samples with an array of length 1,000).
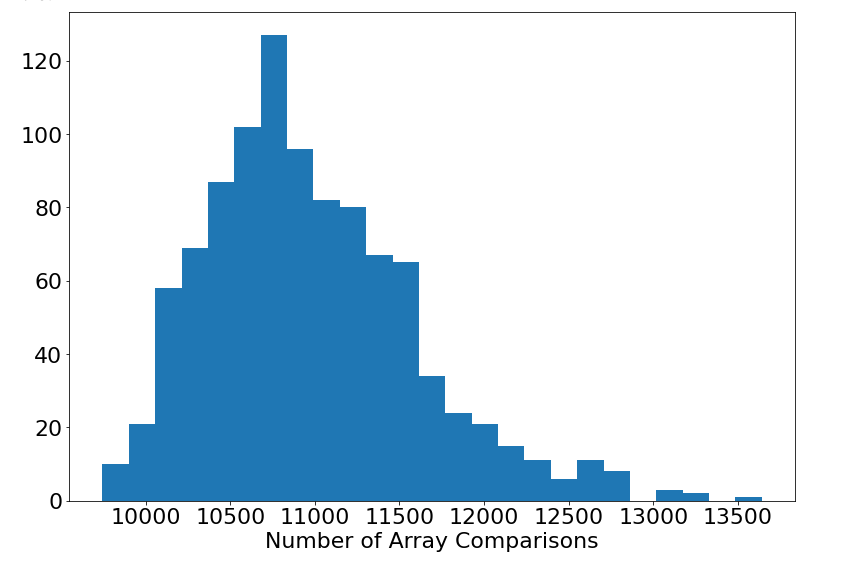
The deterministic QuickSort for this array takes 10,457 array comparisons as well which is close to the mean which is expected since we ran this over a random input.
However, let’s look into the most problematic case for QuickSort which is the reverse-sorted array. The deterministic version of QuickSort takes 499,500 array comparisons with is quite mammoth, but Randomized QuickSort’s run-time on the same reverse-sorted array is given by the following distribution over 1,000 samples again.
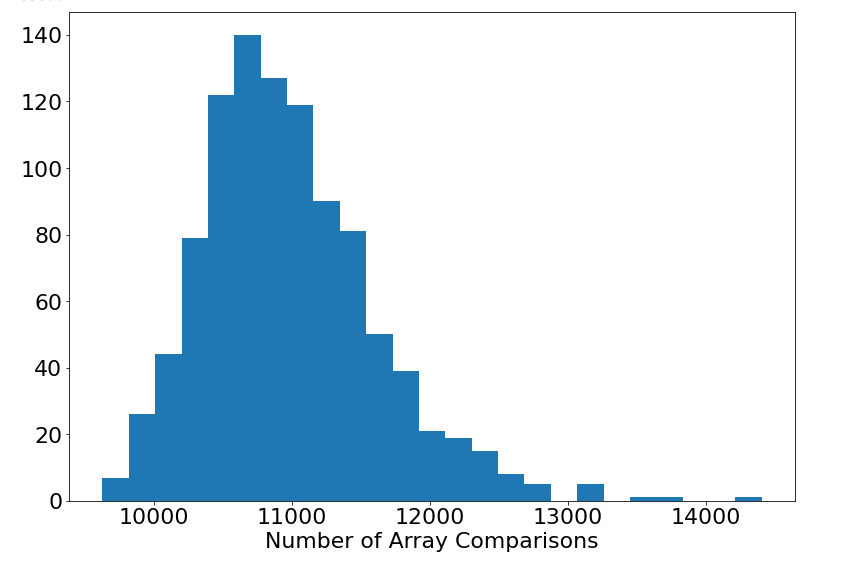
The result here is amazing introducing a stark contrast. We never even require more than 15,000 array comparisons to sort the previously problematic reverse-sorted array. This is an extreme example, but it also presents the extreme benefits of randomization and its power of generalizing an algorithm’s utility regardless of the input.
Thus we emphasize the randomized version due to this extra guarantee we have that enhances our algorithm’s general effectiveness and speed. The discussion in this section aimed to provide some empirical motivation in this light.
Brute-Force Analysis
Consider an array of  elements. Now suppose we have chosen a pivot
elements. Now suppose we have chosen a pivot  from uniformly at random, and subsequently partitioned the array into sub-arrays
from uniformly at random, and subsequently partitioned the array into sub-arrays  and
and  where includes all the elements of (excluding ) that are at most and includes all elements of that are greater than . Let
where includes all the elements of (excluding ) that are at most and includes all elements of that are greater than . Let  be the run-time of Randomized QuickSort on array of elements. From the preceding post on Randomized QuickSort (found here), we realize that
be the run-time of Randomized QuickSort on array of elements. From the preceding post on Randomized QuickSort (found here), we realize that

considering that it takes  time to generate the partitions by comparing every element of to the chosen pivot .
time to generate the partitions by comparing every element of to the chosen pivot .
To find our expected run-time, we can simply consider that is a random variable since of course its value is dependent on the randomness of the pivot’s choice, so we want to find ![\EX[T(n)]](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-1faa0790578dd2b0cac5922871b63a9a_l3.png "Rendered by QuickLaTeX.com") , where
, where ![\EX[.]](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-3788e2cc7d3f5c81a555c956ce79fa0f_l3.png "Rendered by QuickLaTeX.com") denotes expectation. So it further follows by the definition of expectation that
denotes expectation. So it further follows by the definition of expectation that
![\begin{align*} \EX[T(n)] = \sum_{k = 0}^n \lp \Pr[|R| = k] \rp \lp T(n - k - 1) + T(k) + O(n) \rp \end{align*}](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-43102d990a6dbbd95ff812b655ee4dd1_l3.png "Rendered by QuickLaTeX.com")
since we can consider  to be a random variable since it depends on the random variable . Now in order to compute the above expression, we need to understand the distribution of . Observe that for there to be precisely
to be a random variable since it depends on the random variable . Now in order to compute the above expression, we need to understand the distribution of . Observe that for there to be precisely  elements in that are greater than the uniformly chosen at random pivot, must be the
elements in that are greater than the uniformly chosen at random pivot, must be the  ‘th element of
‘th element of  (the sorted version of ), denoted by
(the sorted version of ), denoted by  , which follows that
, which follows that
![\begin{align*} \Pr[|R| = k] = \Pr[A^*_{n - k} = p] = \frac{1}{n} \end{align*}](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-4e126332ca4d9dc4417354912b561b16_l3.png "Rendered by QuickLaTeX.com")
since is chosen uniformly at random from . Thus by substituting to an above expression we finally achieve
![\begin{align*} \EX[T(n)] &= \frac{1}{n} \sum_{k = 0}^n \lp T(n - k - 1) + T(k) + O(n) \rp \\ &= O(n) + \frac{1}{n} \sum_{k = 0}^n \lp T(n - k - 1) + T(k) \rp \end{align*}](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-77cfd15344fc7e08ce00004cf67b6d06_l3.png "Rendered by QuickLaTeX.com")
and fully computing this expression is a very lengthy process and provides little intuition or satisfaction to understand why the average case performs so well in comparison to the worst-case run-time, so we avoid further computation with this brute-force method.
Preliminaries of a Simpler Analysis
Implicitly, we have been defining run-time considering that the array comparison operation (the action of comparing two elements in an array) is the most expensive operation in the algorithm since we are only moving around elements of the input array in the process of sorting, and that operation occurs only when we make a comparison. Thus, under this assumption (which of course is very well-founded), by simply computing the expected number of array comparisons on some fixed input array, we can realize the expected run-time of Randomized QuickSort.
In regards to notation, let’s continue to suppose that denotes the sorted array of the input array , and of course, assume that the length of the array is .
We define the random variable  to indicate whether
to indicate whether  is compared to
is compared to  in the computation of Randomized QuickSort. Note that the comparison between two elements in the array can happen at most once since one must be the pivot and will be omitted from both and .
in the computation of Randomized QuickSort. Note that the comparison between two elements in the array can happen at most once since one must be the pivot and will be omitted from both and .
Considering the most expensive operation being the comparison of two array elements, computing the number of array comparisons is equivalent to the run-time. Thus ![\EX\left[ \sum_{i < j} X_{i, j} \right]](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-565d8d1fe641e4520c919bd2cc0417f1_l3.png "Rendered by QuickLaTeX.com") is the expected the run-time of Randomized QuickSort. By the Linearity of Expectation, we get
is the expected the run-time of Randomized QuickSort. By the Linearity of Expectation, we get
![\begin{align*} \EX\left[ \sum_{i < j} X_{i, j} \right] = \sum_{i < j} \EX[X_{i, j}]. \end{align*}](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-3c586b58bc214ca7778f9bf85eafd89f_l3.png "Rendered by QuickLaTeX.com")
Thus, it should be sufficient to compute ![\EX[X_{i, j}]](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-9a5bf159056f2d7403f40aa0a00c5987_l3.png "Rendered by QuickLaTeX.com") for any
for any  .
.
The Probabilistic Analysis
In our following computation, we cleverly utilize the pivot’s ability to separate an array into and .
Lemma: For any , we have ![\EX[X_{i, j}] = \frac{2}{j - i + 1}](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-c19921e26dd3da36d48f692918ade512_l3.png "Rendered by QuickLaTeX.com") .
.
Proof: We prove this by induction on the size of the array, denoted by . In the base case of  , we only have s
, we only have s and
and  , thus
, thus  . This is consistent because Randomized QuickSort will compare the only two elements in the array in order to sort them, and thus
. This is consistent because Randomized QuickSort will compare the only two elements in the array in order to sort them, and thus ![\EX[X_{i, j}] = 1](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-1b0924ff9ed4ffa155bcee45eadcb0e3_l3.png "Rendered by QuickLaTeX.com") .
.
Choose arbitrary  , and assume the inductive hypothesis for all arrays of size less than . Further, since is in indicator (i.e. it is equal to 1 if true and 0 if false), we can write
, and assume the inductive hypothesis for all arrays of size less than . Further, since is in indicator (i.e. it is equal to 1 if true and 0 if false), we can write
![\begin{align*} \EX[X_{i, j}] = \Pr[X_{i, j} = 1]. \end{align*}](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-c40aa3e28d41c7221b84658bb2e0be33_l3.png "Rendered by QuickLaTeX.com")
Let the first pivot of Randomized QuickSort on the array be the element , and let and be the corresponding “left” and “right” side of after pivoting. Further note that since and since is sorted, we get  . Essentially, we can consider three cases for which we informally depict below:
. Essentially, we can consider three cases for which we informally depict below:
![\begin{align*} A^* &= [\cdots A^*_i \cdots A^*_j \cdots p \cdots] \\ A^* &= [\cdots p \cdots A^*_i \cdots A^*_j \cdots] \\ A^* &= [\cdots A^*_i \cdots p \cdots A^*_j \cdots] \end{align*}](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-680ee8a5124ca0f6462a2fb11a616cdc_l3.png "Rendered by QuickLaTeX.com")
Therefore, by the Law of Total Probability, we can alternatively write
![\begin{align*} \Pr[X_{i, j} = 1] &= \Pr[X_{i, j} = 1 \mid A^*_j < p] \, \Pr[A^*_j < p] \\ &\quad + \Pr[X_{i, j} = 1 \mid A^*_i > p] \, \Pr[A^*_i > p] \\ &\quad + \Pr[X_{i, j} = 1 \mid A^*_i \le p \le A^*_j] \, \Pr[A^*_i \le p \le A^*_j]. \end{align*}](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-718542290fc31a31a795afd6e287bb56_l3.png "Rendered by QuickLaTeX.com")
If  , then that means both and
, then that means both and  are in , and so by induction on , we have
are in , and so by induction on , we have
![\begin{align*} \Pr[X_{i, j} = 1 \mid A^*_j < p] = \frac{2}{j - i + 1}. \end{align*}](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-dcb4114d6b700b6d871b49db20f90c07_l3.png "Rendered by QuickLaTeX.com")
Similarly, if  , then both and are in , and so
, then both and are in , and so
![\begin{align*} \Pr[X_{i, j} = 1 \mid A^*_i > p] = \frac{2}{j - i + 1}. \end{align*}](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-18c965f5db2300eb317b668b14fc1cbd_l3.png "Rendered by QuickLaTeX.com")
In the case where  , the only way and are being compared to each other are if either one is the pivot (because otherwise, would be in and would be in and they would never be compared in the Randomized QuickSort algorithm). Thus, the probability of either being the pivot is
, the only way and are being compared to each other are if either one is the pivot (because otherwise, would be in and would be in and they would never be compared in the Randomized QuickSort algorithm). Thus, the probability of either being the pivot is  by counting, so
by counting, so
![\begin{align*} \Pr[X_{i, j} = 1 \mid A^*_i < p < A^*_j] = \frac{2}{j - i + 1}. \end{align*}](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-42e7a6be47c5d53ef684c7a53dad5db1_l3.png "Rendered by QuickLaTeX.com")
Hence, by substition,
![\begin{align*} \Pr[X_{i, j} = 1] &= \frac{2}{j - i + 1} \left( \Pr[A^*_j < p] + \Pr[A^*_i > p] + \Pr[A^*_i \le p \le A^*_j] \right) \\&= \frac{2}{j - i + 1}. \end{align*}](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-e8c3b1e2d7600449f369ef5cbea813b8_l3.png "Rendered by QuickLaTeX.com")
as claimed. 
Thus bringing it all together, we have the central theorem below.
Theorem: The expected run-time of Randomized QuickSort is ; in particular,
![\begin{align*} \sum_{i < j} \EX[X_{i, j}] \le 2nH_n \end{align*}](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-699065bc7e73762f5efb58426ddba2a9_l3.png "Rendered by QuickLaTeX.com")
where  is the Harmonic Series.
is the Harmonic Series.
Proof: Note that we consider the number of comparisons as equivalent to the run-time of Randomized QuickSort, and we wish to compute the expected run-time, i.e. to compute ![\sum_{i < j} \EX[X_{i, j}]](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-f59ef08709ef2e36bf89f426fca44a88_l3.png "Rendered by QuickLaTeX.com") . We can expand as follows by the previous lemma:
. We can expand as follows by the previous lemma:
![\begin{align*}\sum_{i < j} \EX[X_{i, j}] &= \sum_{i < j} \frac{2}{j - i + 1} \\&= \sum_{i = 1}^{n - 1} \sum_{j = i + 1}^{n} \frac{2}{j - i + 1} \\&= \sum_{i = 1}^{n - 1} \sum_{k = 1}^{n - i} \frac{2}{k + 1} \\&= \sum_{i = 1}^{n - 1} 2(H_{n - i} - 1) \\&\le 2nH_n,\end{align*}](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-891d4890f00b111a40f5d1ca28eaf21c_l3.png "Rendered by QuickLaTeX.com")
as required by adding  . Now we need to upper bound in order to get a more complete bound. Note that
. Now we need to upper bound in order to get a more complete bound. Note that  . Notice that the function
. Notice that the function  monotonically decreases as
monotonically decreases as  increases, so
increases, so

To visualize this, consider the following plot where the orange-filled area is  , the green-filled area is
, the green-filled area is  , and the red-filled area is
, and the red-filled area is  .
.
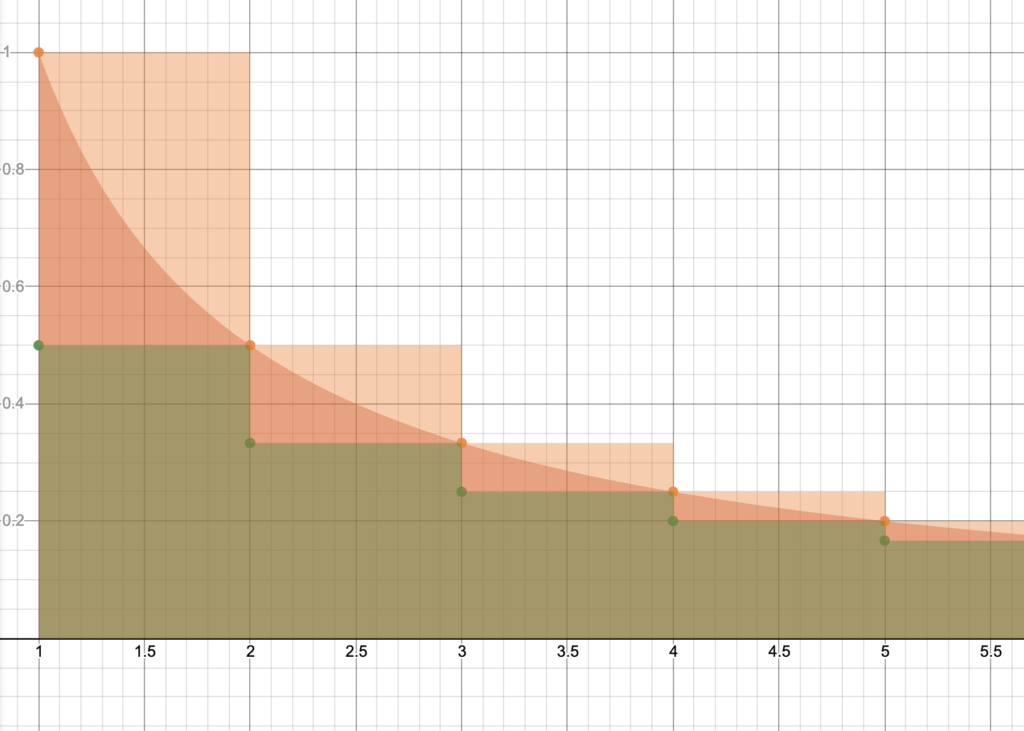
Since  , we have
, we have  . Thus we can substitue to get
. Thus we can substitue to get
![\begin{align*}\sum_{i < j} \EX[X_{i, j}] = O(n \log n)\end{align*}](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-2f086df918ef2ae5ae388b4fff3d7ce8_l3.png "Rendered by QuickLaTeX.com")
as desired. Hence, Randomized QuickSort has an expected run-time of .
Thus we recognize that the expected run-time of the Randomized QuickSort algorithm is quite optimal, asymptotically on par with the best sorting algorithms. In fact, sorting algorithms that only utilize comparisons all have a run-time of at least  . Furthermore, the run-time of Randomized QuickSort, in general, is concentrated around the expected run-time which we discuss in another blog. Although in practical use, this sorting algorithm has proven itself as widely efficient, it is always special to see it backed by theoretical knowledge as we have here.
. Furthermore, the run-time of Randomized QuickSort, in general, is concentrated around the expected run-time which we discuss in another blog. Although in practical use, this sorting algorithm has proven itself as widely efficient, it is always special to see it backed by theoretical knowledge as we have here.
Recent Comments