
There are many methods of introducing structure to random variables in Probability Theory, and traditionally we call this structure a property, and one such property is its distribution. Phrases like “coming from this distribution” or “they distribute as such” or “these variables make this distribution” all refer to this property. In this post, we will go into the most common distribution and introduce basic facts for each one.
This post is part of a multi-post series going over such distributions, and for more detailed analysis and writing, look out for the next few posts.
Many of the explanations and facts are referenced from Probability and Computing by Mitzenmacher and Upfal and William Feller’s classic An Introduction to Probability Theory.
Probability Theory Basics
Before we begin, let’s start from the very basics. Let’s define our sample space  which is the set of all possible samples. Now an event
which is the set of all possible samples. Now an event  is a subset of the sample space, i.e. it is a collection of samples. Further, we can define any event in the power set of , denoted by
is a subset of the sample space, i.e. it is a collection of samples. Further, we can define any event in the power set of , denoted by  , which is the set of all subsets of . Intuitively, an event entails a set of samples that represent when that event happens. For example, in the sample space of weather forecasts of every day in the year, we have an event
, which is the set of all subsets of . Intuitively, an event entails a set of samples that represent when that event happens. For example, in the sample space of weather forecasts of every day in the year, we have an event  when it rains, so is the set of all days in the year when it rained.
when it rains, so is the set of all days in the year when it rained.
Having defined the sample space and event, let’s define probability. Intuitively, it signifies how likely an event is to occur, and mathematically we define it as follows.
Definition 1: A probability function is a function  where
where
- for all events , we have
![0 \le \Pr[A] \le 1](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-19a21386627d736c258f3f9cc5e6493a_l3.png "Rendered by QuickLaTeX.com") ;
; - we have
![\Pr[\Omega] = 1](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-ca20abc56efab592eb3023e3c3da840b_l3.png "Rendered by QuickLaTeX.com") ; and
; and - for any countably infinite mutually disjoint collection of events
 , we have
, we have
![\begin{align*}\Pr\lp \bigcup_{i \ge 1} A_i \rp = \sum_{i \ge 1} \Pr[A_i].\end{align*}](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-211c6ec53c45e3d4c3d583cf835a2711_l3.png "Rendered by QuickLaTeX.com")
Now we’ll define the random variable, which will be playing a key role in all our probabilistic analyses. The following definition is extremely abstract primarily because we want it to have flexible structure for future use.
Definition 2: A random variable  over is a real-valued function
over is a real-valued function  .
.
Notice that we can let be the event where some random variable  where
where  , and then we see that
, and then we see that ![\Pr[A] = \Pr[X = x]](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-a0bbe2c0f4e9873b7f4e101a40d397f8_l3.png "Rendered by QuickLaTeX.com") and to understand this probability, we require some knowledge of the randomness. That is described by the distribution which essentially defines the probability function for a random variable. We will explore these facts soon, but before we get there let’s continue with our introduction to the basics of probability theory.
and to understand this probability, we require some knowledge of the randomness. That is described by the distribution which essentially defines the probability function for a random variable. We will explore these facts soon, but before we get there let’s continue with our introduction to the basics of probability theory.
Now we will define expectation, and its mathematical definition is just like its literal one. We denote by ![\EX[X]](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-f73c65a1365e7e14def04a80edd742cd_l3.png "Rendered by QuickLaTeX.com") , and by definition it is
, and by definition it is
![\begin{align*}\EX[X] = \sum_x x\Pr[X = x],\end{align*}](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-833ffb5a719b56f082b41ba251587567_l3.png "Rendered by QuickLaTeX.com")
and in most of our uses of expectation, the sum converges to a real number. Essentially, is the expected value of .
We must introduce the two key facts; note the first one is more of a definition, and the second has a brief proof.
Fact 1 (Conditional Equivalence): For two events  and
and  , we have
, we have
![\[\Pr[A_1 \cap A_2] = \Pr[A_1] \Pr[A_2 | A_1].\]](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-3a6712596caba9461934daececcf6103_l3.png "Rendered by QuickLaTeX.com")
Fact 2 (Linearity of Expectation): For two random variables and  ,
,
![\[\EX[X + Y] = \EX[X] + \EX[Y].\]](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-86cca351d811cdde0f4039ff1a3fc418_l3.png "Rendered by QuickLaTeX.com")
Proof: By definition we have where  :
:
![\begin{align*} \EX[X + Y] &= \sum_z z \Pr[X + Y = z] \\&= \sum_{x, y} (x + y) \Pr[X = x \text{ and } Y = y] \\&= \sum_{x, y} x \Pr[X = x \text{ and } Y = y] \\&\quad\quad+ \sum_{x, y} y \Pr[Y = y\text{ and } X = x] \\&= \sum_{x, y} x \Pr[X = x] \Pr[Y = y \mid X = x] \\&\quad\quad+ \sum_{x, y} y \Pr[Y = y] \Pr[X = x \mid Y = y] \\&= \sum_x x \Pr[X = x] \sum_y \Pr[Y = y \mid X = x] \\&\quad\quad+ \sum_y y \Pr[Y = y] \sum_x \Pr[X = x \mid Y = y] \\&= \sum_x x \Pr[X = x] (1) + \sum_y y \Pr[Y = y] (1) \\&= \EX[X] + \EX[Y], \end{align*}](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-68d4102efe67009f801d93814c88ea82_l3.png "Rendered by QuickLaTeX.com")
where the fourth line comes from Conditional Equivalence, the sixth from the fact that ![\sum_s \Pr[S = s \mid T = t] = 1](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-62a073a979545dca27e03b61dd23e2a3_l3.png "Rendered by QuickLaTeX.com") for fixed
for fixed  and random variables
and random variables  and
and  , and the last line by the definition of expectation. Thus we have proved the linearity of expectations.
, and the last line by the definition of expectation. Thus we have proved the linearity of expectations. 
Note that the form ![\Pr[B | C]](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-397490de8d868f56c23227edbb252f30_l3.png "Rendered by QuickLaTeX.com") for events
for events  and
and  is the probability that occurs conditioned on occurring, and we call this conditional probability and it is defined by Conditional Equivalence.
is the probability that occurs conditioned on occurring, and we call this conditional probability and it is defined by Conditional Equivalence.
Lastly, let’s introduce the notion of variance. We denote it by ![\var[X]](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-6f0ea57777d4e15fccdc22720249c2b7_l3.png "Rendered by QuickLaTeX.com") and define it as
and define it as
![\begin{align*}\var[X] = \EX[(X - \EX[X])^2].\end{align*}](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-bdc47b2cf8c6cb86ea11a206a838d721_l3.png "Rendered by QuickLaTeX.com")
And the important expression to note is ![X - \EX[X]](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-301e6d2432748f0c9178c20ceaa83cf8_l3.png "Rendered by QuickLaTeX.com") which is essentially the deviance of the random variable from its expectation, and then we square it to weed out the role of the sign. Thus we define the variance as the expected deviance squared.
which is essentially the deviance of the random variable from its expectation, and then we square it to weed out the role of the sign. Thus we define the variance as the expected deviance squared.
Further, by Linearity of Expectation, we get
![\begin{align*}\var[X] &= \EX[(X - \EX[X])^2] \\&= \EX[X^2 - 2X\EX[X] + (\EX[X])^2] \\&= \EX[X^2] - \EX[2X\EX[X]] + \EX[(\EX[X])^2] \\&= \EX[X^2] - 2\EX[X]\cdot\EX[X] + (\EX[X])^2 \\&= \EX[X^2] - (\EX[X])^2.\end{align*}](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-4b8fad729ae160296d26825b11daa947_l3.png "Rendered by QuickLaTeX.com")
Note that we used the fact that the expectation of the expectation is simply the expectation, e.g. ![\EX[\EX[X]] = \EX[X]](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-4676de0c81e2556ff0b15686106ae1ab_l3.png "Rendered by QuickLaTeX.com") . Thus we derived another definition of variance as
. Thus we derived another definition of variance as
![\[\var[X] = \EX[X^2] - (\EX[X])^2.\]](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-443ab3b9fb86f37614c4496e507b5c60_l3.png "Rendered by QuickLaTeX.com")
Now another form that most are usually familiar with is the standard deviation which, denoted by the  , is defined as
, is defined as
![\[\sigma[X] = \sqrt{\var[X]}.\]](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-ba1559adcb23288792c3aa8268e65c36_l3.png "Rendered by QuickLaTeX.com")
We will frequently use these terms when we go into concentration inequalities, but they are introduced here to enhance our introduction to probability distributions.
Uniform Distribution
We are familiar with the coin toss or the dice roll, and what’s common with most of these experiments is that there is an equal chance for any option: there is a  chance that a coin flips as head or tail and there is a
chance that a coin flips as head or tail and there is a  chance that a dice rolls as a
chance that a dice rolls as a  ,
,  ,
,  ,
,  ,
,  , or
, or  . This is what we call the uniform distribution, where all options have equal probability.
. This is what we call the uniform distribution, where all options have equal probability.
Definition 3: A random variable from the uniform distribution with parameter  is defined by the probability distribution for all
is defined by the probability distribution for all  , we have
, we have
![\[\Pr[X = x] = \frac{1}{n}.\]](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-5a7fc80790d5aa48589e233b260180e8_l3.png "Rendered by QuickLaTeX.com")
The parameter signifies the number of options we have in our distribution, and thus the probability that is any one of the options is  .
.
A generalization of the uniform distribution is called the categorical distribution or the multinomial distribution which will be discussed in an upcoming post.
Normal Distribution and Bell Curve
We have all heard of the “curve,” usually in the setting of grading or assorting data in the real world. Please note this curve is not the same as the curve of the COVID-19 pandemic (in full swing while this post was written); that curve refers to the derivative of the logistic curve. The curve I am referring is the famous Bell Curve which receives its name by how it is shaped.
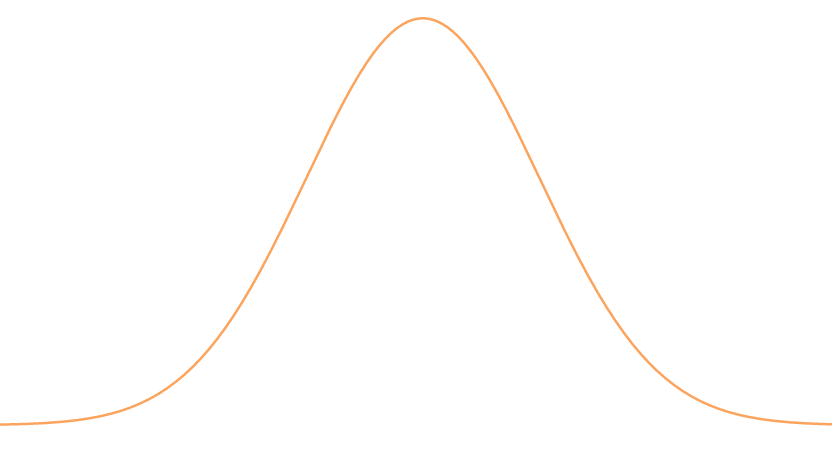
The above figure is a generic Bell Curve, and notice that it is symmetric and its peak is where its mean stands. Further, notice that the “width” or “stretch” of the curve would say something about deviance as well.
This curve is the Probability Density Function (PDF) of the Normal distribution. Let’s unpack that a little. Remember how we defined probability as a function; the PDF is merely another way of referring to that function. This curve is essentially a definition of the function, and that definition is what we call the Normal distribution. It’s called the normal distribution since many observations of nature fit into this curve. For example, the heights of males fit this curve, or even how well students score on a test; the examples are endless, and this is why theorists tend to spend a lot of time understanding this distribution to gain a better sense of our world in general.
Along with the physical examples, the features of this distribution are quite convenient in analysis which we will explore deeply in an upcoming post, going over the mechanics of this key distribution.
On a final note, this distribution is also called the Gaussian distribution, and the Bell Curve the Gaussian Curve, and this notation is more scientific and more commonly used in research.
Bernoulli Random Variables and Binomial Distribution
Finally, we can begin getting to the real content of this blog post. In all our discussion on these distributions we plan to give basic intuition and short examples, and for more formal mathematics and elaborate examples look out for more blog posts focused on each distribution.
First, let’s talk about one of the most common random variables. A lot of events can be converted to decision events, i.e. either the event occurs or doesn’t. For example, let’s again take the example of the weather, and narrow it down to either it rained or didn’t. We can let some variable indicate whether it rained or not by

In this case, we call this variable a Bernoulli because it is either 0 or 1. We can also call an indicator because it indicates some implied event. These variables are the most commonly used in randomized algorithms.
A generalization of the Bernoulli is the Binomial random variable which comes from the Binomial distribution. An example of the distribution is shown below.

As we can see, this is a discrete distribution, and the full specifics of this will be discussed in another post. There are continuous approximations of this variable such as the Beta distribution, but those are reserved for another time.
Geometric Distribution
Now we are venturing into the range of the less commonly discussed distributions. What if we had a random variable that was memory invariant, i.e. the distribution of the random variable remains the same under all conditions? This is precisely what the Geometric random variable offers. To clarify, for the Geometric random variable , we have
![\begin{align*} \Pr[X = n + k \mid X > k] = \Pr[X = k] \end{align*}](https://balaramdb.com/wp-content/ql-cache/quicklatex.com-b93c3e8d0de09e81cb05f8299f1bffe2_l3.png "Rendered by QuickLaTeX.com")
for all and  . Isn’t that pretty sweet?
. Isn’t that pretty sweet?
To graphically depict this phenomenon, the following is an example of the Geometric distribution.
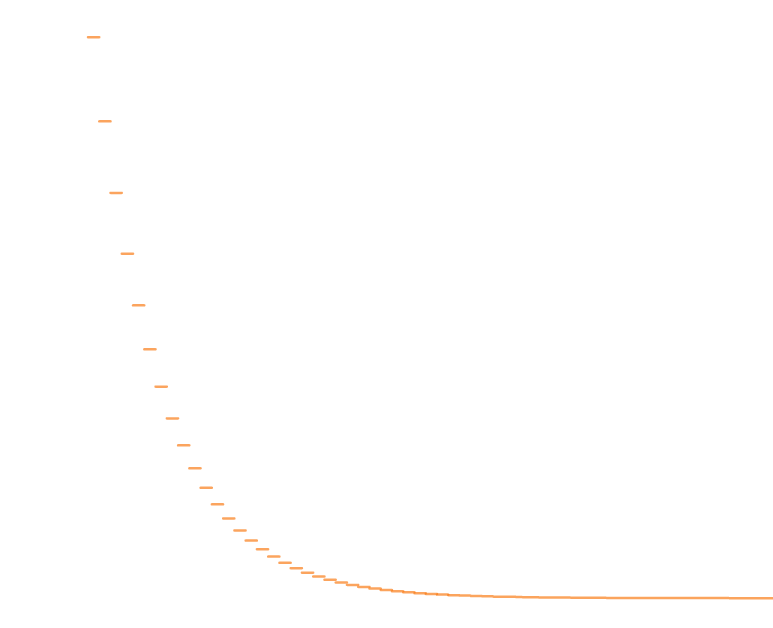
Since the area under the PDF must be one, keeping this memoryless property is extremely special. It essentially says that by starting from any point on the x-axis, the curve will look the same if scaled according to the probability at that point. This special property is a gift of the exponential.
The continuous version of the Geometric distribution is called the Exponential Distribution, and its definition is similar to the former. Look out for more posts regarding this distribution and the Coupon Collector Problem which is a famous problem applying Geometric random variables in its analysis.
Poisson Distribution
We won’t be able to explore the applications of the Poisson distribution, but we will try to give a brief introduction to a setting that uses Poissons, as they are called. The following image is an example of the Poisson distribution.
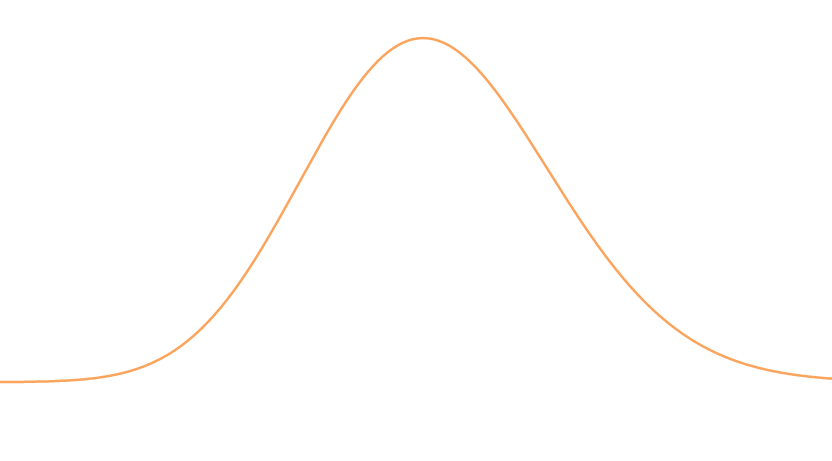
It may difficult to notice, but its not truly symmetric, yet its shape mimics the Binomial distribution and the Normal distribution, and we will see that we use this distribution to approximate other distributions to gain more freedom with independence.
Furthermore, this distribution is highly used in the Balls and Bins setting: where we have bins and randomly assort  balls to the bins. In order to solve problems in this setting like the Max Load problem — to find the maximum number of balls in a bin — we can use Poisson Approximation. Note that hash function analysis is essentially a case of Balls and Bins, and this marks one of the prominent uses of this setting and Poissons.
balls to the bins. In order to solve problems in this setting like the Max Load problem — to find the maximum number of balls in a bin — we can use Poisson Approximation. Note that hash function analysis is essentially a case of Balls and Bins, and this marks one of the prominent uses of this setting and Poissons.
Looking Forward
I plan to eventually go into the definitions of these distributions, the expectation, and variance that come with the distributions, and some elaborate examples to cement the intuition and theory. Note that, the reason I am beginning with such an introduction to Probability Theory is that it will form the basis of a lot of Randomized Algorithms, and I plan to go into those in the future. One example of such a field would be Property Testing, where we try to determine whether some given distribution matches some target distribution. Furthermore, simply knowing these distributions can advance mathematical literacy and aide in most future reading, and this post will serve as a brief reference for my future posts.
Thank you for reading through my first official blog post!
2 thoughts on “Introduction to Probability Distributions”